Open Source · GPL-3.0
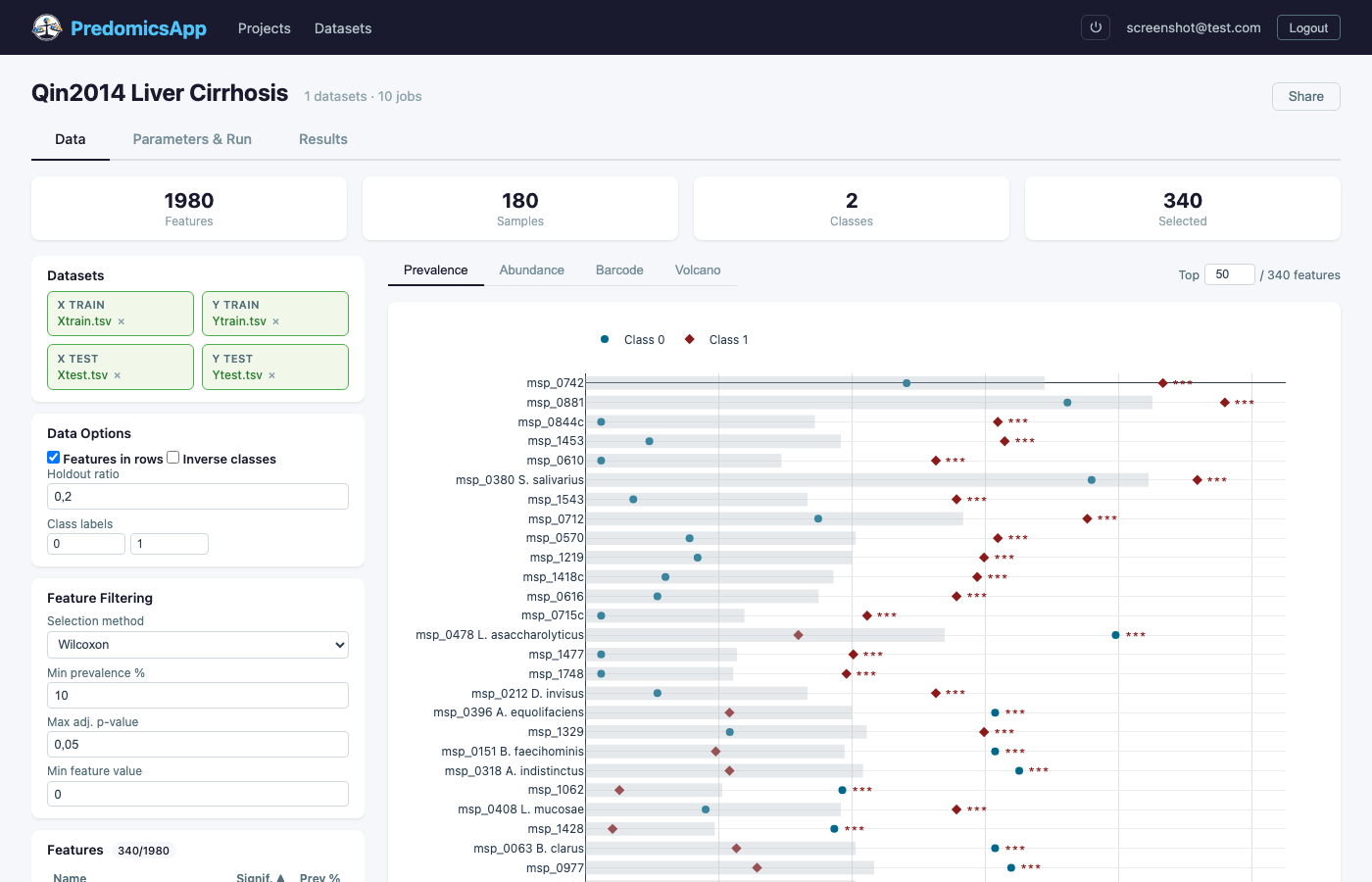
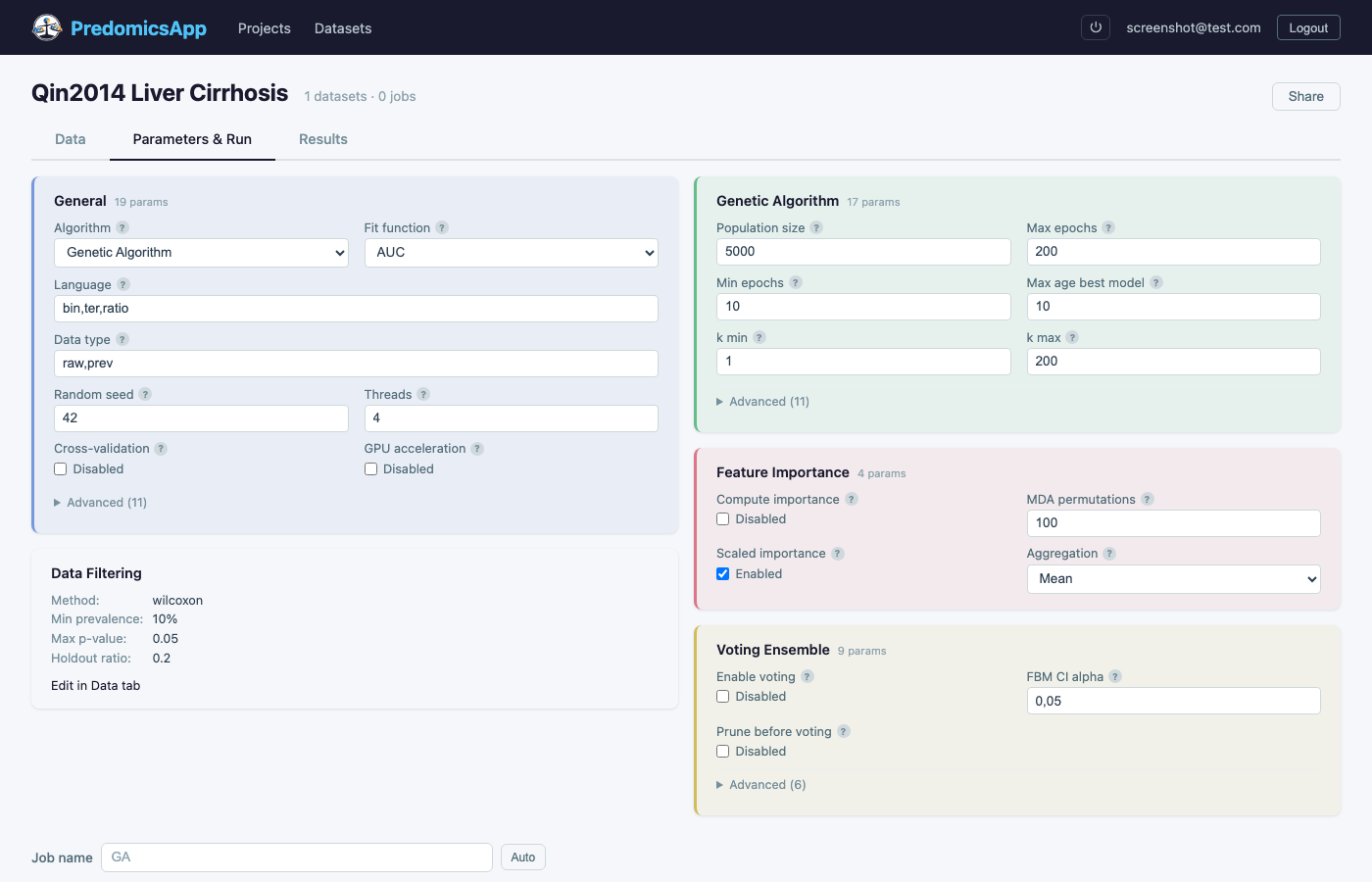
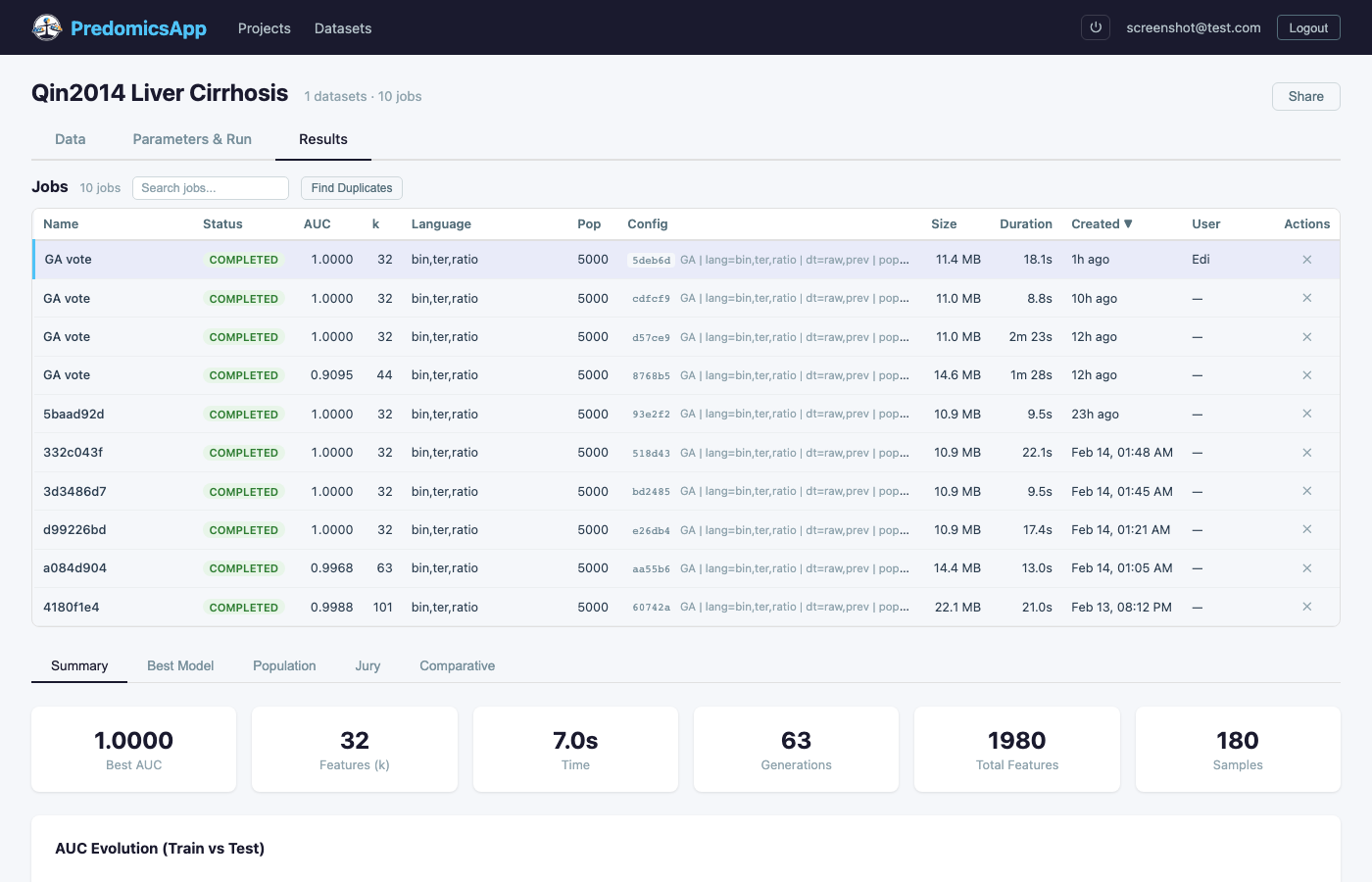
Predictive Models
from Omics Data
Discover minimal-feature biomarker signatures from high-dimensional omics data using evolutionary algorithms — interpretable, parsimonious, and blazing fast.
0x
Faster (Rust)
<1%
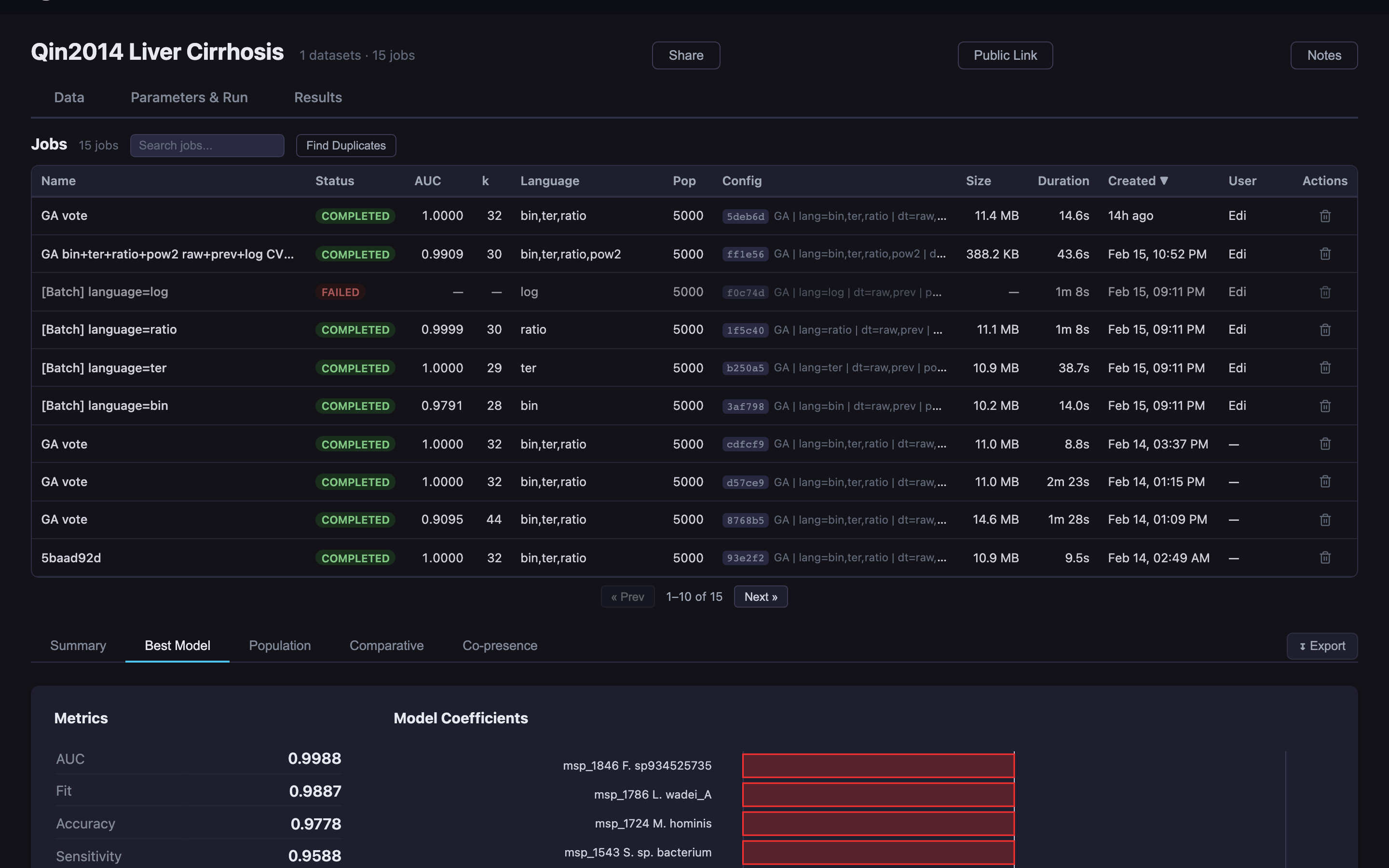
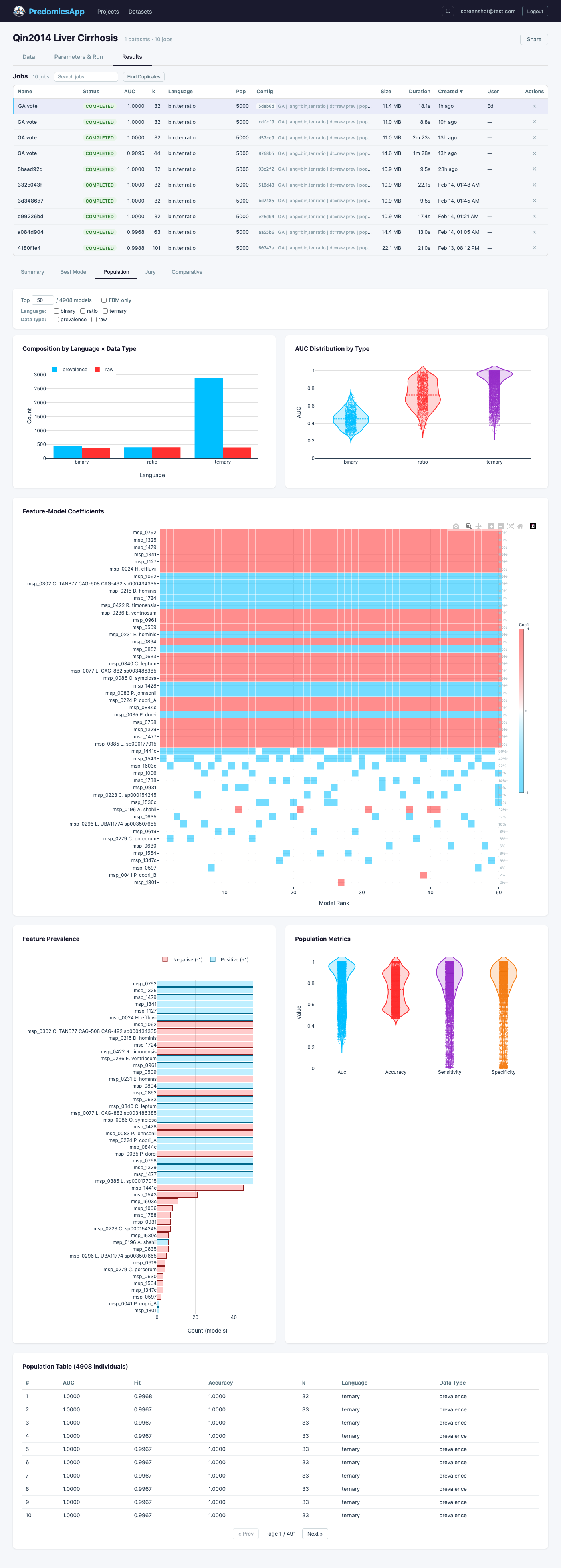
Feature selection
0
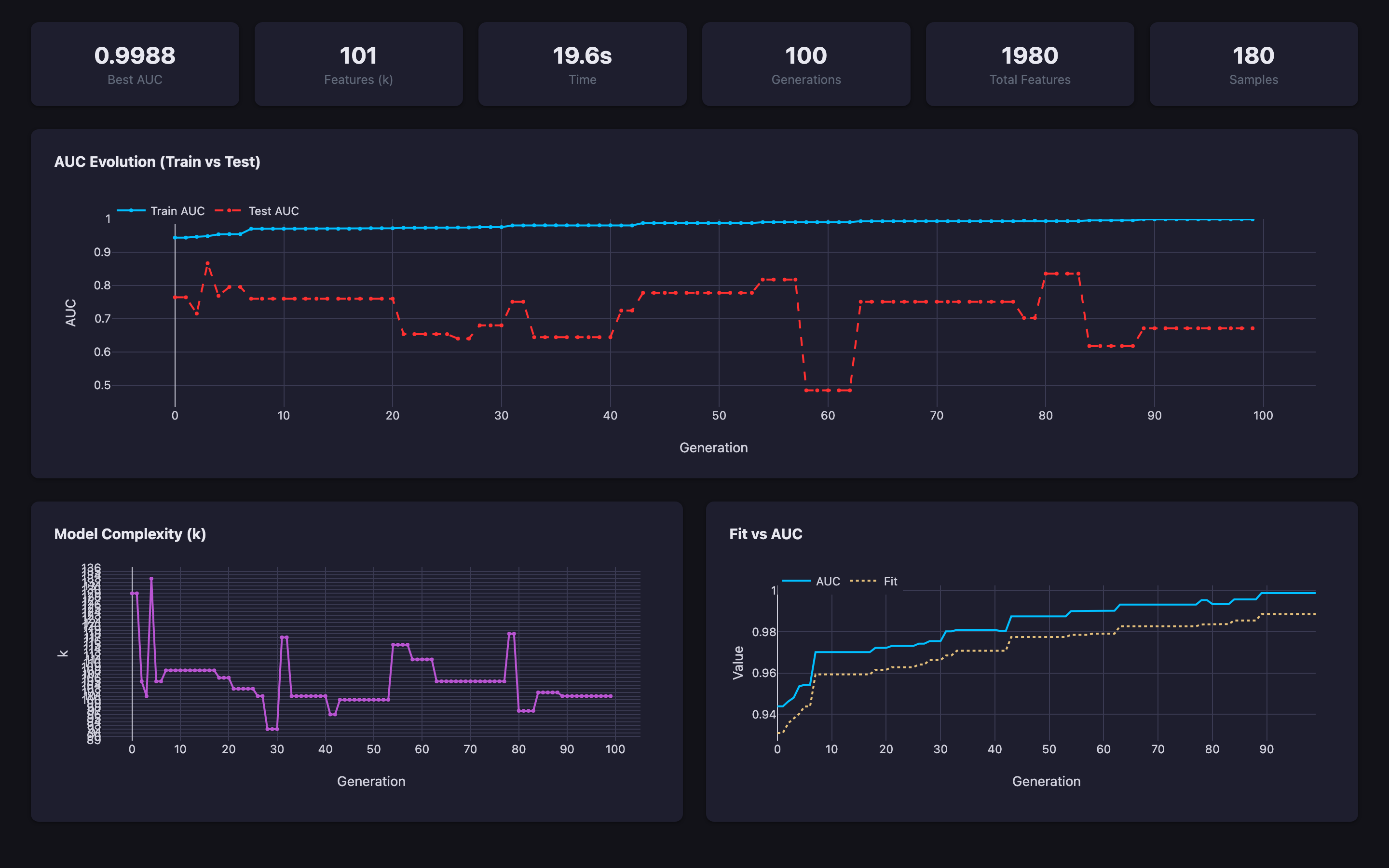
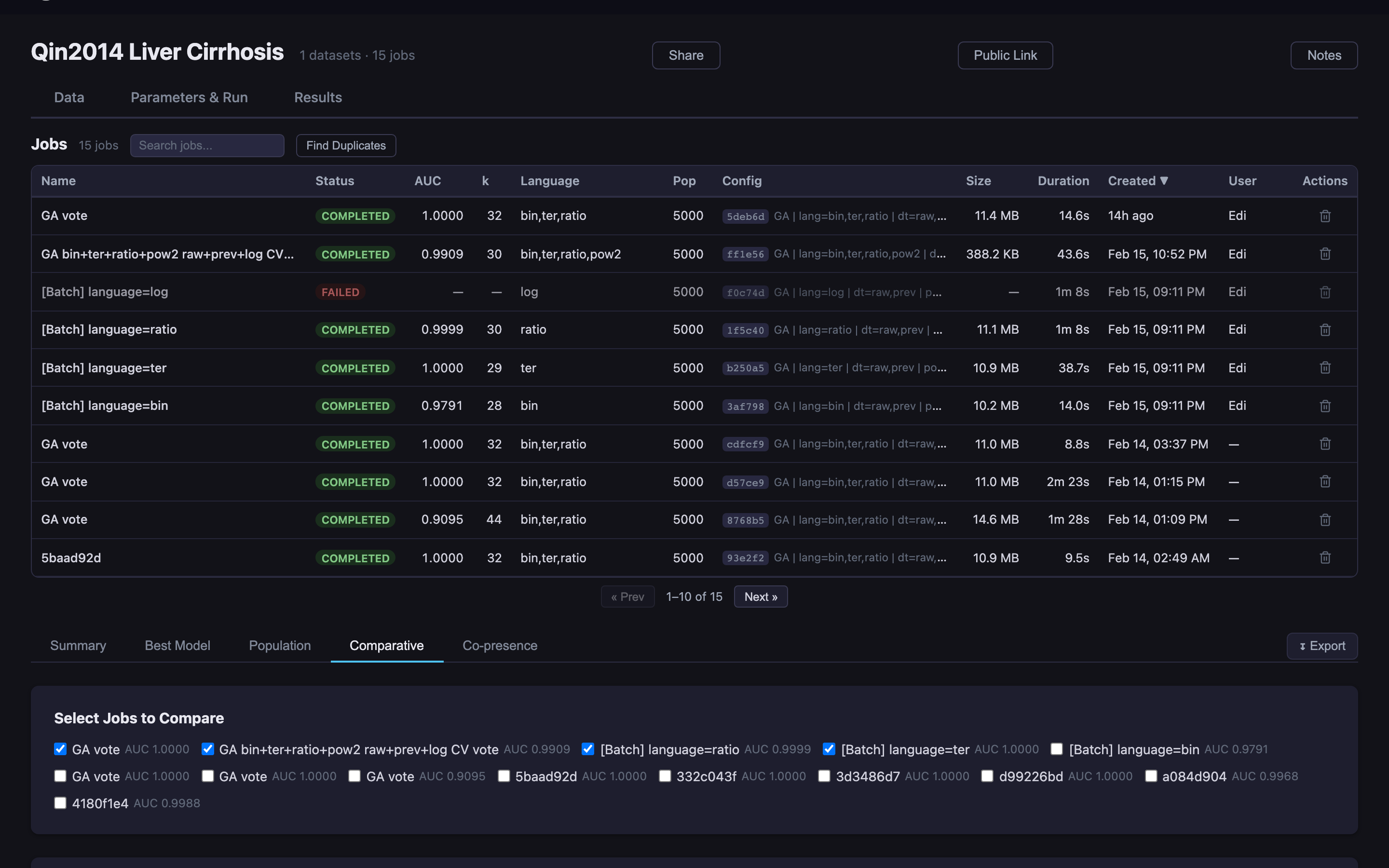
Search algorithms
Open
Source & Free